Retail Data Platform
This project is a demo data platform architecture built to simulate a retail environment.It demonstrates ingestion, storage, transformation, and analytics using modern data engineering tools.
Project Brief
A demo data platform that simulates a retail environment. It showcases ingestion, storage, transformations with dbt, orchestration with Airflow, analytics in Streamlit, CI/CD with GitHub Actions, and documentation (architecture + lineage).
Approach
- Planning & Goals
- Framed the project as an end-to-end data engineering demo for a retail analytics pipeline
- Defined key objectives: simulate data ingestion → transformation → analytics using modern data stack tools
- Outlined modular architecture to support reproducibility and scalability (Dockerized services)
- Architecture Design
- Planned containerized setup for Postgres, Airflow, and Streamlit for isolated, reproducible environments
- Chose dbt for SQL-based transformations, testing, and lineage tracking
- Mapped daily orchestration DAG in Airflow to automate ingestion → load → transform → test
- Implementation
- Developed Python ingestion script using Faker to generate synthetic retail data (customers, products, sales)
- Loaded datasets into Postgres via batch pipeline and validated integrity with dbt tests
- Implemented dbt models (staging + marts) to create curated, analytics-ready tables
- Configured Airflow DAG to automate end-to-end pipeline runs
- Visualization & Analytics
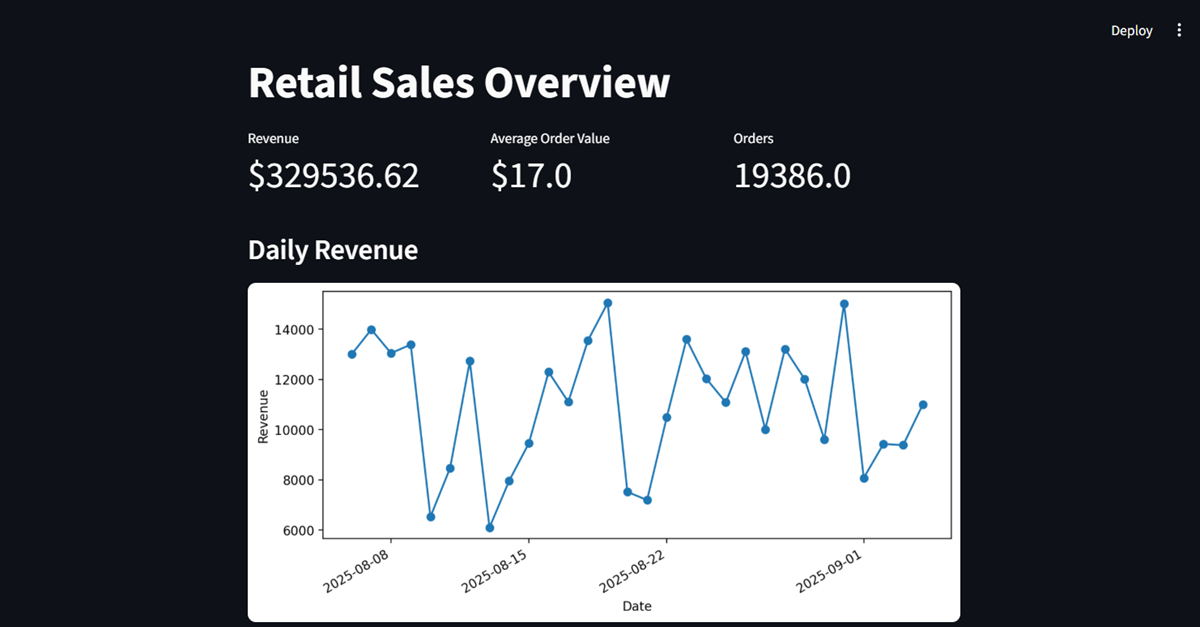
- Built Streamlit dashboard to visualize KPIs like daily revenue, top categories, and customer segmentation
- Integrated aggregated tables from dbt for real-time metric refreshes
- Ensured dashboard responsiveness and lightweight deployment for demos
- Testing & CI/CD
- Created dbt test suite: not_null, unique, relationships, and accepted_values constraints
- Automated dbt parse + Python lint on each commit using GitHub Actions
- Used small synthetic datasets for quick regression validation of DAG and models
- Deployment & Documentation
- Deployed the stack locally via Docker Compose for consistent multi-container orchestration
- Documented architecture with diagrams (Airflow DAG, dbt lineage, Streamlit screenshots)
- Configured environment variables (.env) for database connections and credentials
- Project Duration (Estimate)
- Part-time (evenings/weekends): 6–8 weeks for full pipeline (data → dbt → Airflow → Streamlit)
- Additional 2–3 weeks for CI/CD integration, documentation, and dashboard polishing
Features
- Synthetic Ingestion: Python + Faker to generate retail datasets
- Data Warehouse: PostgreSQL with staged → marts layers
- Transformations: dbt models with tests and lineage
- Orchestration: Airflow DAG (generate → load → dbt run/test)
- Analytics: Streamlit dashboard for KPIs & trends
- CI/CD: GitHub Actions for dbt parse & Python lint
- Docs: architecture diagram and lineage screenshots
Tools & Technologies
Python 3.12Postgres 14dbt-postgresApache Airflow 2.9StreamlitDockerdocker-composeGitHub Actions